Отчёт по моделям
Главная страница кумулятивной оценки моделей. Здесь всё агрегируется по реальным sample, а не по отдельным run. Один профиль = одна модель + один режим RAG.
Модели
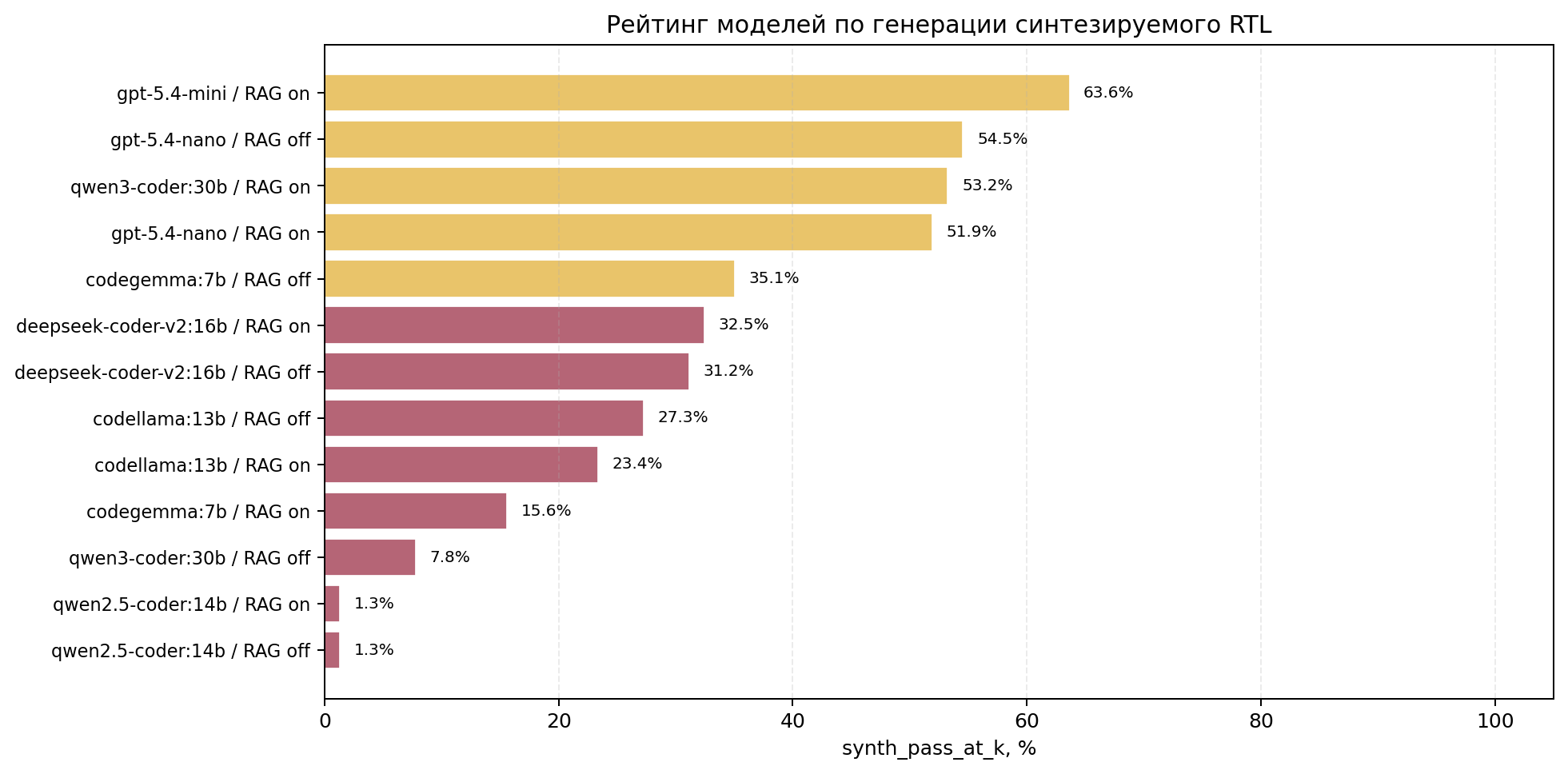
Основной рейтинг строится по synth_pass_at_k, потому что нас в первую очередь интересует способность модели генерировать синтезируемый RTL.
| Модель | RAG | synth_pass_at_k | final_success_at_k | functional_pass_at_k | Задач | Sample | samples_per_task | Бенчмарки |
|---|---|---|---|---|---|---|---|---|
| gpt-5.4-mini | RAG on | 63.6% | 63.6% | 66.2% | 77 | 1752 | 22.75 | ilyasov, rtllm |
| gpt-5.4-nano | RAG off | 54.5% | 54.5% | 54.5% | 77 | 770 | 10.0 | ilyasov, rtllm |
| qwen3-coder:30b | RAG on | 53.2% | 53.2% | 75.3% | 77 | 2441 | 31.7 | ilyasov, rtllm |
| gpt-5.4-nano | RAG on | 51.9% | 51.9% | 54.5% | 77 | 770 | 10.0 | ilyasov, rtllm |
| codegemma:7b | RAG off | 35.1% | 35.1% | 45.5% | 77 | 770 | 10.0 | ilyasov, rtllm |
| deepseek-coder-v2:16b | RAG on | 32.5% | 32.5% | 63.6% | 77 | 770 | 10.0 | ilyasov, rtllm |
| deepseek-coder-v2:16b | RAG off | 31.2% | 31.2% | 53.2% | 77 | 770 | 10.0 | ilyasov, rtllm |
| codellama:13b | RAG off | 27.3% | 27.3% | 28.6% | 77 | 1540 | 20.0 | ilyasov, rtllm |
| codellama:13b | RAG on | 23.4% | 23.4% | 41.6% | 77 | 770 | 10.0 | ilyasov, rtllm |
| codegemma:7b | RAG on | 15.6% | 15.6% | 40.3% | 77 | 770 | 10.0 | ilyasov, rtllm |
| qwen3-coder:30b | RAG off | 7.8% | 7.8% | 29.9% | 77 | 770 | 10.0 | ilyasov, rtllm |
| qwen2.5-coder:14b | RAG off | 1.3% | 1.3% | 2.6% | 77 | 770 | 10.0 | ilyasov, rtllm |
| qwen2.5-coder:14b | RAG on | 1.3% | 1.3% | 2.6% | 77 | 770 | 10.0 | ilyasov, rtllm |
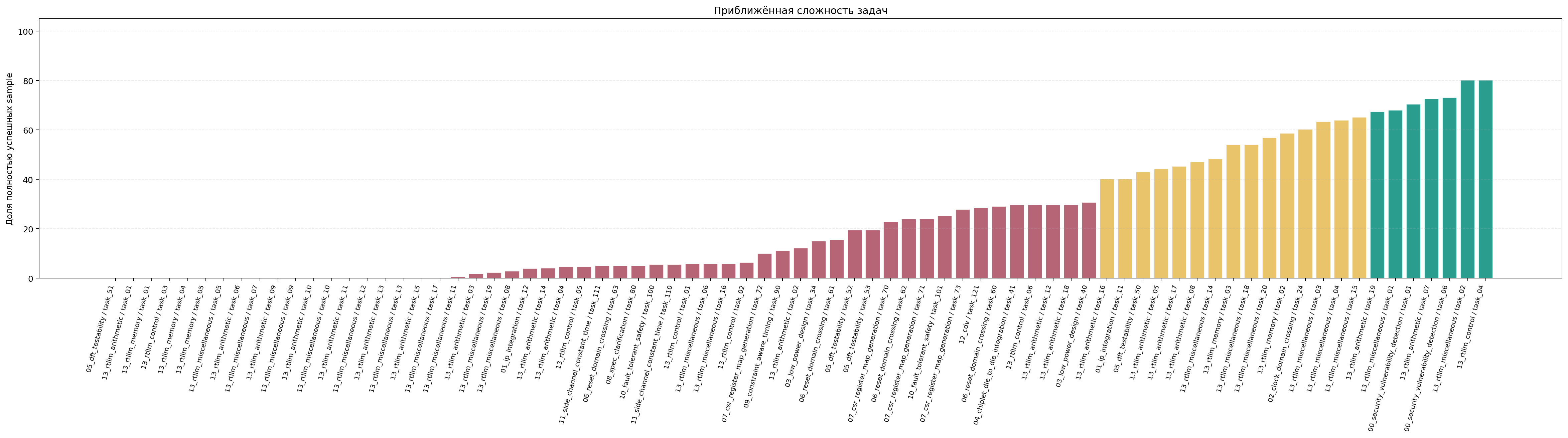
Сложность задач
Приближённая сложность задачи по всем модельным профилям. Метрика: final_success_samples / samples_total. Чем ниже доля, тем задача тяжелее.
CDV/coverage-driven verification исключен из RTL-срезов: это задача на генерацию тестовых последовательностей, а не Verilog RTL.
Рейтинг моделей
Диаграмма ранжирует профили по synth_pass_at_k: доле задач, где модель хотя бы в одной попытке сгенерировала синтезируемый RTL. Рядом показано сравнение этапов functional_pass_at_k, synth_pass_at_k и final_success_at_k.
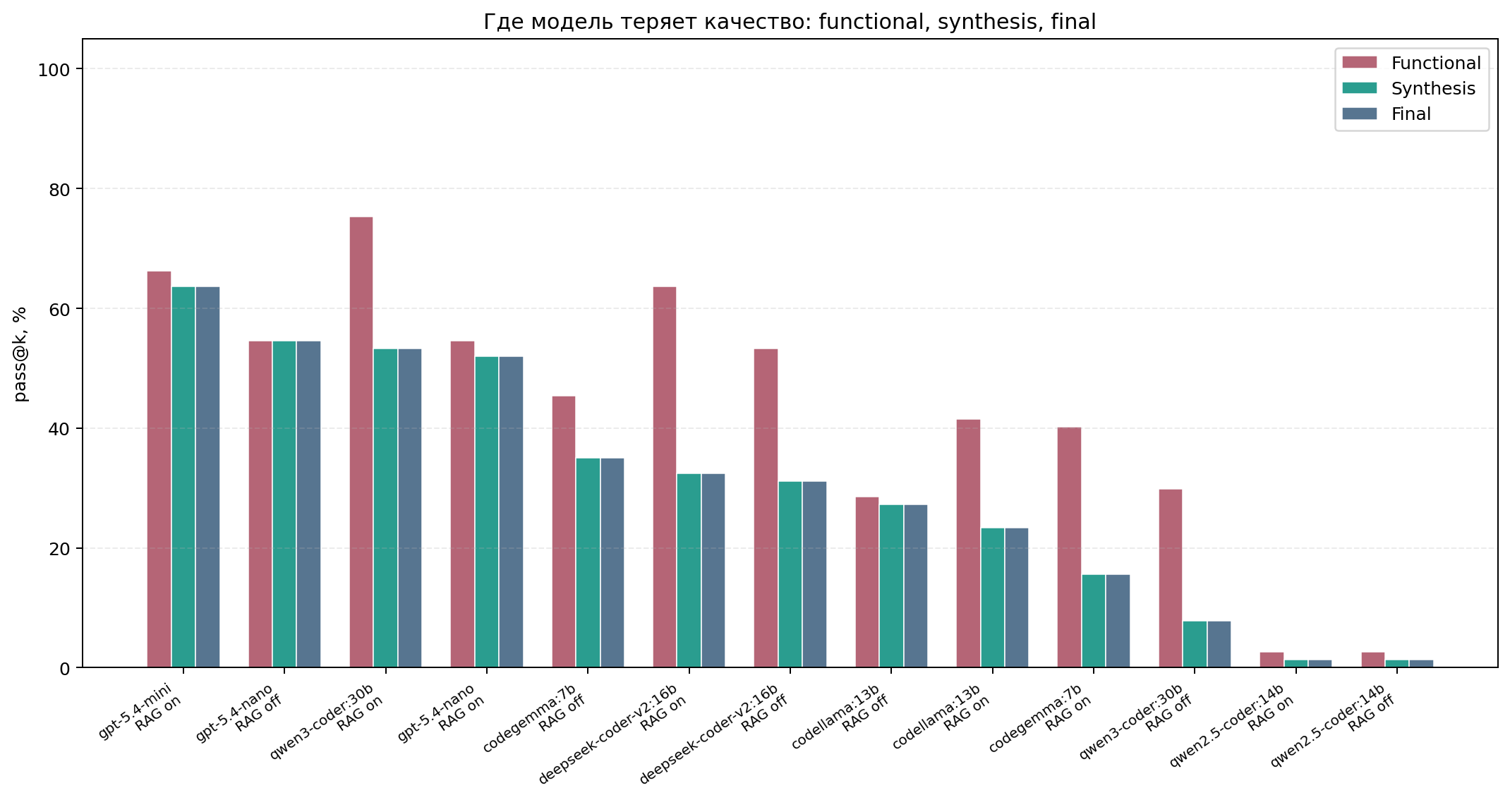
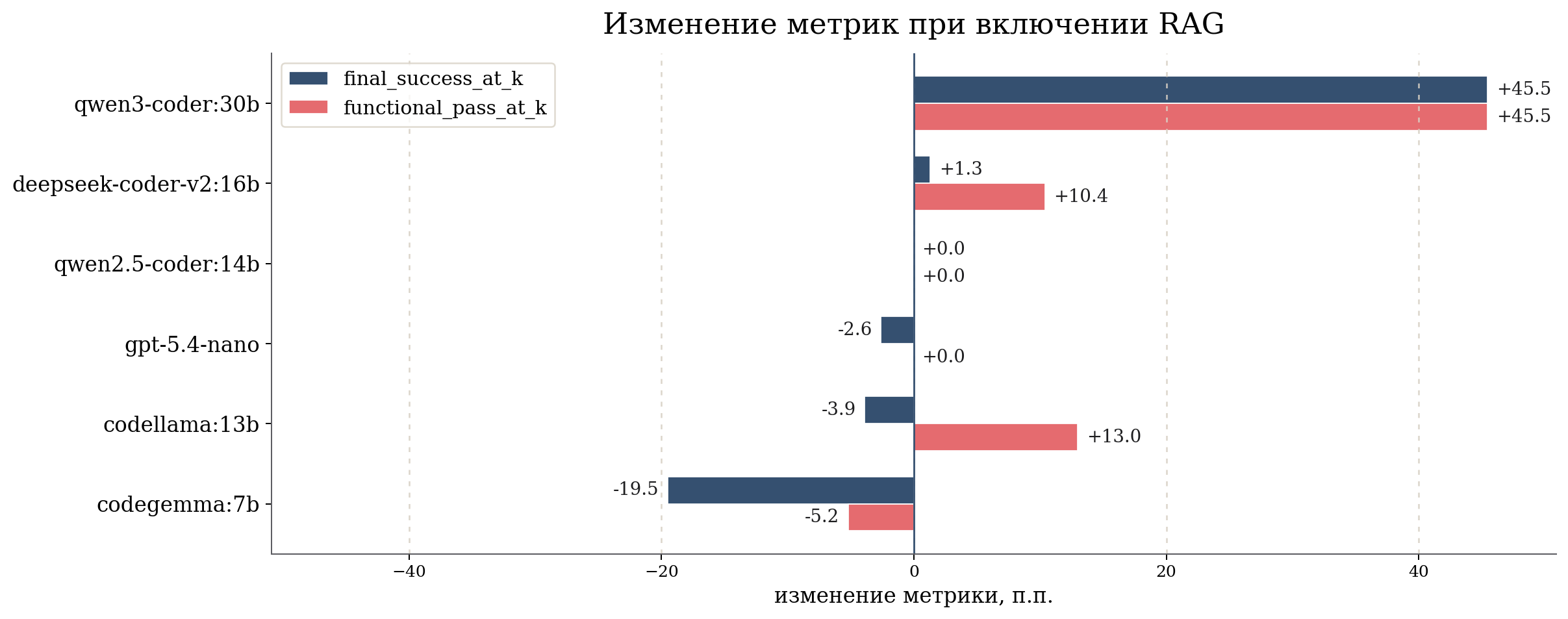
Изменение метрик при включении RAG
Для моделей, у которых есть оба профиля, показана разница RAG on - RAG off в процентных пунктах. Цвета приведены к той же палитре, что и диаграммы сравнения профилей.
Типы задач по всем LLM
Агрегация по доменам для всех модельных профилей. Метрика: final_success_samples / samples_total. Это показывает, какие классы задач LLM в целом решают устойчиво, а где чаще возникают проблемы.
CDV/coverage-driven verification здесь не показан, потому что это отдельный класс задач на тестирование и coverage, а не генерация RTL-модуля.
Сейчас показана сводка по всем моделям и режимам.
| Тип задач | Что проверяет | Задач | Успех | Диаграмма | Лучший профиль | Худший профиль | Вывод |
|---|---|---|---|---|---|---|---|
| Преобразование формата данныхrtllm misc data conversion | Задачи на преобразование представления данных. Например, параллельное слово нужно выдать по одному биту за такт, последовательные биты нужно собрать обратно в слово, или два 8-битных слова нужно объединить в одно 16-битное. Проверяются порядок битов и момент готовности результата. | 3 | 0.0% | gpt-5.4-mini / RAG on (0.0%) | gpt-5.4-mini / RAG on (0.0%) | проблемный тип | |
| Прикладная управляющая логикаrtllm misc control examples | Прикладные управляющие автоматы, например календарь или светофор. Такие задачи проверяют длительные счетчики времени, переходы между режимами и реакцию на внешние события, например кнопку пешехода. | 2 | 0.3% | gpt-5.4-nano / RAG off (5.0%) | gpt-5.4-mini / RAG on (0.0%) | проблемный тип | |
| Детекторы событий и синхронизацияrtllm misc detection sync | Задачи на обнаружение событий и синхронизацию сигналов. Нужно сформировать однотактный импульс при фронте сигнала, обнаружить короткий pulse или безопасно перенести сигнал между доменами. Основная сложность - не растянуть импульс и не потерять событие. | 3 | 2.9% | codegemma:7b / RAG off (50.0%) | gpt-5.4-mini / RAG on (0.0%) | проблемный тип | |
| Уточнение и восстановление спецификацииspec clarification | Задачи на точное восстановление смысла спецификации. Требуется не просто написать счетчик или флаг, а правильно понять приоритеты одновременных событий: например, что важнее - очистка, инкремент или переполнение. Такие задачи проверяют, умеет ли модель внимательно читать условия и не додумывать поведение. | 1 | 5.0% | gpt-5.4-mini / RAG on (23.1%) | gpt-5.4-nano / RAG off (0.0%) | проблемный тип | |
| Защита от side-channel и constant-time логикаside channel constant time | Задачи на защиту от побочных каналов. Нужно реализовать схему так, чтобы время выполнения не зависело от секретных данных. Например, сравнение или поиск должны занимать фиксированное число тактов, без раннего выхода при первом совпадении. Это важно, потому что по времени реакции атакующий может восстановить секрет. | 2 | 5.3% | gpt-5.4-mini / RAG on (23.1%) | gpt-5.4-nano / RAG on (0.0%) | проблемный тип | |
| Учет timing-ограниченийconstraint aware timing | Задачи на RTL с ограничениями по задержкам и конвейеризации. Модель должна не только посчитать выражение, но и разложить вычисление по тактам, выдержать нужную задержку результата и правильно вести сигнал valid, который показывает, что выходные данные готовы. | 1 | 11.2% | gpt-5.4-mini / RAG on (46.2%) | gpt-5.4-nano / RAG on (0.0%) | проблемный тип | |
| Отказоустойчивость и safety-логикаfault tolerant safety | Задачи на отказоустойчивую и safety-логику. Требуется не только хранить или считать данные, но и обнаруживать ошибки: например, через контрольные биты, дублированный счетчик или сравнение двух копий логики. Проверяется, умеет ли модель формировать сигнал ошибки и переводить схему в безопасное состояние. | 2 | 15.4% | gpt-5.4-nano / RAG on (60.0%) | codegemma:7b / RAG off (0.0%) | проблемный тип | |
| Переходы между reset-доменамиreset domain crossing | Задачи про сбросы в разных тактовых доменах. Сброс может приходить асинхронно, а отпускаться должен синхронно с конкретным clock. Нужно правильно построить цепочки синхронизации и выдержать порядок снятия reset между несколькими доменами, чтобы схема не стартовала в неопределенном состоянии. | 4 | 18.4% | gpt-5.4-mini / RAG on (80.8%) | codegemma:7b / RAG off (0.0%) | проблемный тип | |
| DFT и тестопригодностьdft testability | Задачи на проектирование логики, удобной для тестирования микросхемы после производства. DFT означает Design for Testability. Сюда входят scan-цепочки, JTAG-контроллеры и MBIST-обвязка памяти. Модель должна учитывать обычный режим работы и отдельный тестовый режим. | 4 | 20.5% | gpt-5.4-nano / RAG off (67.5%) | codegemma:7b / RAG off (0.0%) | проблемный тип | |
| Арифметические RTL-блокиrtllm arithmetic | Арифметические RTL-блоки: сумматоры, вычитатели, компараторы, умножители, делители, fixed-point и floating-point операции. Проверяется точность разрядности, переносы, переполнение, знак числа и задержка результата в конвейерных вариантах. | 19 | 21.0% | gpt-5.4-mini / RAG on (45.6%) | qwen3-coder:30b / RAG off (0.0%) | проблемный тип | |
| Управляющая логика RTLrtllm control | Управляющая логика: счетчики, кольцевые счетчики, счетчики Джонсона и конечные автоматы. Конечный автомат - это схема с набором состояний и правилами перехода между ними. Проверяется reset, переходы состояний и момент, когда выходной сигнал должен стать активным. | 6 | 21.1% | codegemma:7b / RAG off (58.3%) | qwen3-coder:30b / RAG off (0.0%) | проблемный тип | |
| CSR и регистровые картыcsr register map generation | Задачи на генерацию блока управляющих и статусных регистров. CSR означает Control and Status Registers. Модель получает карту регистров в виде таблицы, JSON или YAML и должна реализовать доступ по APB или AXI-Lite: адреса, чтение, запись, маски и особые эффекты отдельных битов. | 4 | 21.2% | gpt-5.4-nano / RAG on (80.0%) | codegemma:7b / RAG off (0.0%) | проблемный тип | |
| Интеграция IP-блоковip integration | Задачи на интеграцию готовых интерфейсов и преобразование протоколов. Нужно соединить разные блоки так, чтобы данные и управляющие сигналы передавались без потерь. Часто встречается valid/ready: valid означает, что источник выставил корректные данные, ready означает, что приемник готов их принять. | 2 | 22.1% | gpt-5.4-mini / RAG on (61.5%) | codegemma:7b / RAG off (0.0%) | проблемный тип | |
| Память и буферы RTLrtllm memory | Блоки памяти и сдвига: FIFO, LIFO, сдвиговые регистры, barrel shifter и LFSR. FIFO - очередь первым вошел, первым вышел; LIFO - стек последним вошел, первым вышел. Проверяются указатели, признаки full/empty, циклический переход адресов и последовательное поведение по тактам. | 5 | 22.6% | gpt-5.4-mini / RAG on (40.0%) | qwen3-coder:30b / RAG off (0.0%) | проблемный тип | |
| Low-power designlow power design | Задачи на энергосберегающую RTL-логику. Нужно учитывать домены питания, режим сна, удержание состояния и изоляцию сигналов, когда часть схемы выключена. Модель часто ошибается, если превращает такую задачу в обычный автомат без учета low-power требований. | 2 | 22.9% | gpt-5.4-nano / RAG off (90.0%) | codegemma:7b / RAG off (0.0%) | проблемный тип | |
| Процессорный datapathrtllm misc processor datapath | Процессорные и вычислительные блоки: арифметико-логическое устройство, регистр инструкций и MAC/PE-блок. ALU выбирает операцию по коду команды, MAC выполняет умножение с накоплением. Проверяются коды операций, знаковость и регистровые задержки. | 3 | 23.6% | gpt-5.4-mini / RAG on (33.3%) | codellama:13b / RAG on (0.0%) | проблемный тип | |
| Память внутри miscellaneousrtllm misc memory primitives | Простые блоки памяти внутри RTLLM miscellaneous: RAM и ROM. RAM допускает запись и чтение, ROM только чтение заранее заданных значений. Проверяются адресация, инициализация и синхронность доступа. | 2 | 27.0% | gpt-5.4-mini / RAG on (50.0%) | qwen3-coder:30b / RAG on (0.0%) | проблемный тип | |
| Chiplet / die-to-die интеграцияchiplet die to die integration | Задачи на связь между chiplet-блоками, то есть отдельными кристаллами внутри одной системы. Нужно реализовать обертку интерфейса: wrapper - это слой, который преобразует внутренний формат данных в формат линии связи. Flit - небольшой пакет передачи; payload - полезные данные; control bits - служебные биты. Проверяется упаковка данных и корректный обмен valid/ready. | 1 | 29.6% | gpt-5.4-mini / RAG on (100.0%) | qwen3-coder:30b / RAG on (0.0%) | проблемный тип | |
| Clocking и генераторы сигналовrtllm misc clocking waveform | Задачи на генерацию тактовых и периодических сигналов. Нужно построить счетчики, которые формируют деленную частоту, прямоугольный сигнал или треугольную форму. Важны коэффициент деления, длительность высокого/низкого уровня и корректный reset. | 7 | 54.7% | codegemma:7b / RAG off (87.1%) | qwen3-coder:30b / RAG off (0.0%) | средняя сложность | |
| Переходы между clock-доменамиclock domain crossing | Задачи на передачу данных между разными тактовыми доменами. Тактовые домены могут быть асинхронны, поэтому нельзя напрямую пропускать многобитную шину через обычные триггеры. Обычно синхронизируют управляющий сигнал, а данные захватывают только когда известно, что они стабильны. | 1 | 60.3% | gpt-5.4-mini / RAG on (100.0%) | codellama:13b / RAG on (0.0%) | средняя сложность | |
| Поиск и исправление уязвимостейsecurity vulnerability detection | Задачи на безопасность RTL. Нужно закрыть утечку секретных данных через отладочный выход или правильно разграничить доступ нескольких агентов к одному регистру. Проверяется, понимает ли модель не только функциональное хранение данных, но и security-требование. | 2 | 71.8% | gpt-5.4-mini / RAG on (100.0%) | qwen2.5-coder:14b / RAG off (10.0%) | LLM решают устойчиво |
Краткий ликбез по метрикам
| Metric | Что означает |
|---|---|
extract_pass_at_k | На какой доле задач модель хотя бы раз выдала извлекаемый Verilog. |
syntax_pass_at_k | На какой доле задач модель хотя бы раз дала синтаксически корректный код. |
functional_pass_at_k | На какой доле задач модель хотя бы один раз прошла functional-проверку. |
synth_pass_at_k | На какой доле задач модель хотя бы один раз сгенерировала синтезируемый RTL. Это главный рейтинг. |
final_success_at_k | На какой доле задач модель хотя бы раз полностью прошла всю цепочку. |
functional_pass_rate_samples | Какой процент всех sample проходит functional. Это уже показатель стабильности, а не просто “хотя бы один успех”. |
synth_pass_rate_samples | Какой процент всех sample проходит synthesis. Показывает устойчивость модели на уровне отдельных попыток. |
samples_per_task | Среднее число sample на одну задачу в этом профиле модели. |
final_success_samples | Сколько sample конкретной задачи полностью прошли всю цепочку проверки. |
final_success_rate_samples | Доля полностью успешных sample для конкретной задачи. |